Today, the increasingly widespread use of applications and technological devices connected to the Internet allows for a huge amount of data linked to information and parameters of all kinds, which can be used through processing (Analytics) to favor, for example, maintaining of production efficiencies, improving health by identifying early signs of potential diseases, discovering new drugs, or making our cities more liveable. Considering the massive and soaring diffusion of these technologies, the need to manage and process a mass of data, growing over time, clearly emerges. This huge amount of data (Big Data) is characterized by the so-called 4Vs:
● Volume: Large amounts of data are accessed from multiple sources, including flows from Internet of Things (IoT) devices. With the increase in the number of users and devices, the data collected increases exponentially.
● Velocity: Data is collected at blazing speeds and needs to be handled promptly. A single wearable device for the detection of the individual’s vital parameters can, for example, generate up to 1000 samples per second. The use of specific reporting, analysis and advanced processes creates the need to access data in real time.
● Variety: All kinds of data formats are processed, from structured data found in traditional databases to unstructured data such as text files.
● Veracity: the reliability of the data. How they are representative of reality and the management of inherent discrepancies in all data collected.
In order to manage the challenges of 4V, while maintaining high quality of service despite an increasing number of users and data collected, the processing must necessarily make use of storage and resources that are distributed and accessible through the Internet and through the increasingly widespread Cloud Computing, which is the technology that allows to use, via remote servers, software and hardware resources (such as mass memories for data storage). Cloud Computing offers an answer to the need to compute huge amounts of data
in real time and to make use of “scalable” components and services, capable of being automatically replicated several times, in order to increase or decrease the performance offered as needed, that is, according to the workload. Cloud Computing is scalable both upwards and downwards: therefore, quickly and in some cases, autonomously, it can decrease or increase the resources available to perform a certain function. The storage resources are also scalable and allow management of increasing amounts of data over time.
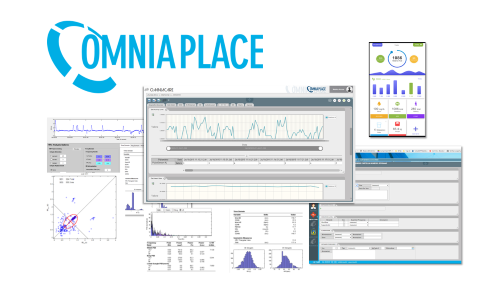
The OMNIAPLACE platform of eResult fully incorporates the paradigms of Big Data and Data Analytics, by implementing a pipeline through which the data flow travels (a processing phase is carried out in each node), as a real-time analysis model to process data in real time and thus allowing the implementation of Artificial Intelligence (AI) and Machine Learning algorithms.
The underlying architecture is designed to be Cloud-agnostic, so as not to be related to a specific provider, but can be implemented using any cloud provider or even multi-vendor services. It is also device-independent, so as to be able to acquire data from multiple devices, developing specific communication interfaces in order to have a harmonized data structure. The architecture is based on Apache Hadoop, an open-source software framework widely used for the reliable, scalable and distributed processing of large data sets on computer clusters, in order to scale from single servers to thousands of machines. The additional open source software has been orchestrated and integrated with Hadoop components from an abstraction layer developed in Python language, in order to create a modular and hierarchical class structure. This allows operating at a higher software level and managing the data pipeline more efficiently, allowing the possible replacement of a software component with a different one, with minimal impact on the processes and functions previously implemented.