Oggi l’uso sempre più ampio e diffuso di applicazioni e dispositivi tecnologici connessi ad Internet consente di avere a disposizione una enorme mole di dati legati a informazioni e parametri di ogni tipo, che possono essere utilizzati tramite elaborazioni (Analytics) per favorire, ad esempio, il mantenimento delle efficienze produttive, la gestione della propria salute individuando precocemente i segnali indicatori di potenziali patologie, scoprire nuovi farmaci, o rendere più vivibili le nostre città. Considerando la diffusione sempre più capillare di queste tecnologie, emerge chiaramente la necessità di gestire ed elaborare una massa di dati, crescente nel tempo. Questa enorme mole di dati (Big Data) è caratterizzata dai cosiddetti 4V:
● Volume: si accede a grandi quantità di dati da più fonti, inclusi i flussi da dispositivi Internet of Things (IoT). Con l’aumento del numero di utenti e dispositivi i dati raccolti aumentano in modo esponenziale.
● Velocità: i dati vengono raccolti a velocità eccezionali e devono essere gestiti prontamente. Un singolo dispositivo indossabile per la rilevazione dei parametri vitali dell’individuo può, ad esempio, generare fino a 1000 campioni al secondo. L’uso di specifiche reportistiche, analisi e processi avanzati crea la necessità di accedere ai dati in tempo reale.
● Varietà: vengono elaborati tutti i tipi di formati di dati, dai dati strutturati presenti nei database tradizionali ai dati non strutturati come i file di testo.
● Veridicità: l’attendibilità dei dati. Come essi sono rappresentativi della realtà e la gestione delle discrepanze inerenti a tutti i dati raccolti.
Per poter gestire le sfide dei 4V, mantenendo alta la qualità del servizio nonostante un numero crescente di utenti e dati raccolti, le elaborazioni devono necessariamente fare uso di risorse di storage e di elaborazione distribuite ed accessibili attraverso Internet e il sempre più diffuso Cloud Computing, ovvero la tecnologia che consente di usufruire, tramite server remoto, di risorse software e hardware (come memorie di massa per l’archiviazione di dati). Il Cloud Computing offre una risposta alla necessità di elaborare
enormi quantità di dati in tempo reale e di fare uso di componenti e servizi “scalabili”, in grado di essere replicati automaticamente più volte per incrementare o diminuire le prestazioni offerte in base alla necessità, cioè al carico di lavoro. Il Cloud Computing è scalabile sia verso l’alto sia verso il basso: quindi, in maniera veloce e in alcuni casi, autonoma, può diminuire o incrementare le risorse a disposizione per svolgere una determinata funzione. Anche le risorse di memorizzazione sono scalabili e consentono di gestire moli di dati crescenti nel tempo.
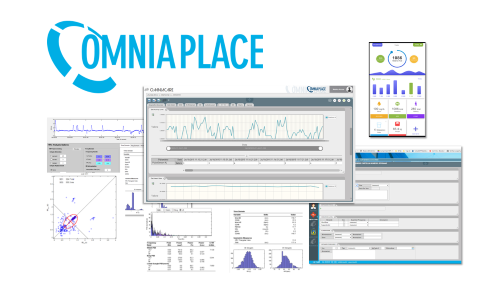
La piattaforma OMNIAPLACE di eResult recepisce a pieno i paradigmi di Big Data e di Data Analytics implementando una pipeline attraverso cui viaggia il flusso di dati (in ogni nodo viene effettuata una fase della elaborazione), come modello di analisi in tempo reale per elaborare i dati in tempo reale e permettere così l’implementazione di algoritmi di Intelligenza Artificiale (AI) e di Machine Learning.
L’architettura alla base è progettata per essere Cloud-agnostic, in modo da non essere correlata a uno specifico provider, ma possa essere implementata utilizzando qualsiasi fornitore di cloud o anche servizi multi-vendor. È anche device-independent, in modo da poter acquisire dati da più dispositivi, sviluppando interfacce di comunicazione specifiche in modo da avere una struttura dati armonizzata. L’architettura si basa su Apache Hadoop, un framework software open-source ampiamente utilizzato per l’elaborazione affidabile, scalabile e distribuita di grandi set di dati su cluster di computer, al fine di poter scalare da singoli server a migliaia di macchine. Il Software open source aggiuntivo è stato orchestrato e integrato con componenti Hadoop da un livello di astrazione sviluppato in linguaggio Python al fine di creare una struttura di classi modulare e gerarchica. Ciò consente di operare a un livello software superiore e di gestire la pipeline di dati in modo più efficiente, permettendo l’eventuale sostituzione di un componente software con uno diverso, con un impatto minimo sui processi e sulle funzioni precedentemente realizzati.